|
■1. データベースとは何か■ Q1.データアクセスインタフェースとはどのようなものですか? Q2.データの形式の変更に対してアプリケーションプログラムに必要な変更が少ないとは、具体的にはどういうことでしょうか? Q3.データベースの管理情報からどのようにしてデータ項目の格納位置を求めるのですか? Q4.ある対象が実体なのか属性なのか明確に決まりますか? Q5.リレーショナルモデルでは、データの構造へのアプリケーションの依存性がより低いと考えられるというのは、具体的にはどういうことでしょうか。 ■2. リレーショナルデータモデル■ Q6.リレーションを表として表示したときのタプルの順序に意味はあるのですか? Q7.定義域とは具体的にはどういうものですか? Q8.同じ内容のタプルが一つのリレーションの中に複数存在することはありますか? Q9.主キーと候補キーの違いは何ですか? Q10.一意性制約と参照制約以外の整合性制約としてどのようなものが考えられますか? ■3. リレーショナルデータベースの設計■ Q11.複数の値をもつ属性が2個以上ある場合は、属性の値をタプルにどのように分解するのですか? Q12.複数のタプルを更新することが何故異状なのですか? Q13.{ 社員番号, プロジェクト番号} → 社員番号 という関数従属性も存在しますか? Q14.リレーションは何故重複排除されるのですか? Q15.リレーションをより高い正規形に分解すると問合せを行うためのリレーショナル演算が複雑になりませんか? ■4. データベース言語SQL■ Q16.SQLのスキーマはリレーショナルモデルのリレーションスキーマに相当するものですか? Q17.異なるスキーマに同じ名前の表を定義できますか? Q18.定義された表を削除したり、定義内容を変更することはできますか? Q19.主キーでない候補キーを定義することはできますか? Q20.条件や選択項目の中に算術演算などの式を指定することはできますか? Q21.問合せの結果に表の列をすべて指定する場合、明示的に全列を羅列する以外に指定方法はないのですか? Q22.IS NULLは = NULLともかけるのですか? Q23.一つのSQL文で複数の異なるスキーマの表に問合せを行うことはできますか? Q24.表全体に対する集計を行うためにはどのようにすればよいのですか? Q25.集合関数を指定する選択項目の名前はどうなるのですか? ■5. データベース管理システム■ Q26.表の結合を実際にDBMSが処理するときも、直積をまず求めて選択するという手続きになるのですか? Q27.最適化の手法にはどのようなものがありますか? Q28.他に有用なアクセス法としてどのようなものがありますか? Q29.B木とB+木の違いはどこですか? Q30.ハッシュ関数はどのように決められていますか? ■6. トランザクション管理■ Q31.ロック方式はどのような仕組みですか? Q32.デッドロックとはどのような現象を言いますか? Q33.ロックはDBMSが自動的にやってくれるのですか? Q34.チェックポイントの間隔はどのように決めればよいのですか? Q35.UNDO、REDO、COMMIT処理、及びROLLBACK処理はDBMSが自動的にやるのですか? ■7. データベースシステムの応用■ Q36.TPモニタとはどのようなソフトウェアですか? Q37.グローバルトランザクションとはどのようなものですか? Q38.並列データベースと分散データベースの違いは何ですか? Q39.XMLへの問合せ言語とはどのようなものですか? Q40.多次元インデクスとはどのようなものですか? ■1. データベースとは何か■ Q1 データアクセスインタフェースとはどのようなものですか? A1 データベースに対して問合せやデータ操作を行うインタフェースはいろいろありますが、多くの場合、レコードを特定するための条件や取り出すデータ項目の名前を一種のプログラム言語によって指定します。このような言語を一般的にデータベース言語と言います。データベース言語によって記述した内容は、アプリケーションプログラムのソーステキスト中に直接指定する方法や、DBMSにアクセスするための関数の引数として渡す方法があります。
データの形式の変更に対してアプリケーションプログラムに必要な変更が少ないとは、具体的にはどういうことでしょうか? A2 レコードに格納するデータの形式を変更する例をイラストに示します。ここでは、社員の情報の中に勤務形態の情報を追加しています。これは比較的単純な変更ですが、この社員情報を扱うアプリケーションプログラムには、いくつかの影響があります。レコードの長さが変わるので、レコードをファイルから受け取るためにアプリケーションプログラムが用意する領域の大きさが変わります。また、レコード内での連絡先の情報を格納する位置が変わるので、アプリケーションプログラムの領域での参照する位置も変わります(多くの場合、アプリケーションプログラムの変数の宣言を変更することになります)。データベースに社員情報を格納する場合は、連絡先の情報を取得するアプリケーションプログラムは、連絡先というデータ項目の名前によって、その情報をデータベースから取り出すので、他のデータ項目が追加されてもこのような影響を受けません。これは、データ項目の名前という論理的な情報を通してデータの取り出しを行うので、レコード中のデータの格納位置というようなレイアウトの情報(物理的な情報)にアプリケーションプログラムの処理が左右されないためです。また、レコードを格納するファイルを変更したり、ファイルを別の場所に作り変えたりする場合も、DBMSの管理情報を変更すればよいのでアプリケーションの変更は必要ありません。 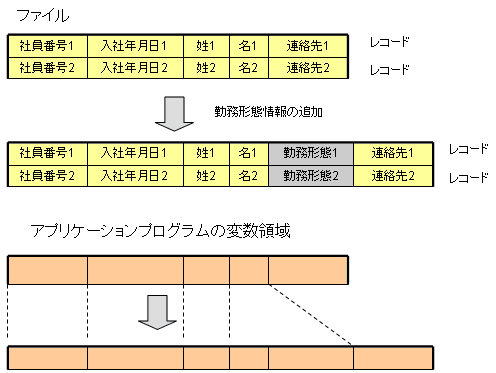
データベースの管理情報からどのようにしてデータ項目の格納位置を求めるのですか? A3 データ項目の値を取り出すための方法は、DBMSによって異なります。あくまで一つの例ですが、レコードを格納するファイルにアクセスするための情報をデータベースの管理情報の中からまず取り出します。ファイルにアクセスするための情報とは、ファイル名やファイルを格納するディレクトリの情報です。ファイルにアクセスできるようになるとレコードを読み込むことが可能になります。データ項目の値を取り出すためには、レコードの中でのデータ項目の位置と長さを求めることが必要です。そのために、管理情報の中のデータ項目の順序番号、データ長の情報を参照します。取り出すデータ項目より前の順序番号のデータ項目のデータ長を足し合わせると、レコード内での取出し対象データ項目の位置が求まります。これと取出し対象データ項目のデータ長を利用してレコードからデータを取り出します。ただし、可変長のデータ項目がある場合は、実際のデータの長さを基にしてデータ項目の位置を算出しレコードごとに位置の情報を管理情報としてレコードに付加する場合もあります。 
ある対象が実体なのか属性なのか明確に決まりますか? A4 ある事実や対象を、実体とするか、関連とするか、属性とするのかは実世界の捉え方によって変わります。従って、実体とするか、関連とするか、属性とするか一意には決まりません。例えば、職位を社員という実体の属性と考えることもできるし、社員と1対多関係の実体と考えることもできます。イラストにその考え方でのER図を示します。この例では職位という実体には職位名称という一つの属性しかありませんが、例えば、さらに職位コードという属性が必要になるような場合は、職位は実体にする方が適切です。 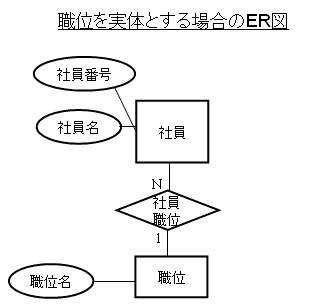
リレーショナルモデルでは、データの構造へのアプリケーションの依存性がより低いと考えられるというのは、具体的にはどういうことでしょうか。 A5 イラストに示した例によってデータベースの構成とアプリケーションプログラムの処理の関係を考えてみます。ここでは、部署と社員という二つのデータベースから東京事業所の社員の一覧を問合せます。ネットワークモデルでは部署レコード型を親レコード型、社員レコード型を子レコード型とする所属親子集合型を通して検索を行います。ここでの問合せでは、事業署名が東京事業所であるすべての部署レコードについて検索を繰り返し、この各検索において、部署レコードに対するすべての社員レコードについての検索を繰り返します。このように、アプリケーションプログラムの処理は、親子関係の階層の数だけの多重ループになります。ネットワークモデルでの問合せ処理は、親子関係の構造に対応した構造になると考えることができます。一方、リレーショナルモデルでは、問合せ結果のレコードの集合を求めて、集合からレコードを一つずつ取り出します。部署と社員という二つのリレーションによるデータベースの構成は、問合せの記述に反映されます。しかし、取り出し処理は一つのループで行われ、アプリケーションプログラムの処理の構造への影響は小さいと考えることができます。 
■2. リレーショナルデータモデル■ Q6 リレーションを表として表示したときのタプルの順序に意味はあるのですか? A6 リレーションは順序関係のないタプルの集合です。つまり、タプルとタプルの間に順序関係は定義されていません。従って、表の中でタプルが表示される順序に意味はありません。表示されるタプルの順序を入れ替えてもリレーションとしては同じです。イラストに示した二つのリレーションは同じリレーションを表します。 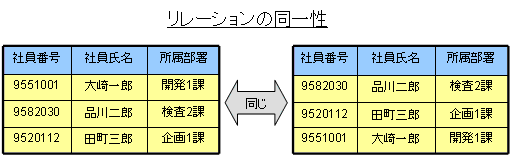
定義域とは具体的にはどういうものですか? A7 ある属性の定義域とは、その属性が取りうる値の集合のことです。例えば、定義域が8文字の文字列であれば、8文字で構成されるすべての文字列の集合になります。定義域が整数であれば、位取り(小数点以下の桁数)が0のすべての数の集合になります。また、例えば定義域が都道府県名であれば、県名を列挙した集合 {'北海道','青森県', ……………,'沖縄県'} になります。
同じ内容のタプルが一つのリレーションの中に複数存在することはありますか? A8 タプルはリレーションの集合です。集合の要素は値によってだけ区別されるので、同じ値の要素は一つの要素とみなされます。従って、同じ内容のタプルは一つの同じタプルとみなされ、複数存在することはありません。
主キーと候補キーの違いは何ですか? A9 リレーションの中で個々のタプルを識別するための属性(又は属性の組)を候補キーといいます。あるタプルの候補キーの属性値(又は属性値の組)は同じリレーションの他のどのタプルのものとも異なっている必要があります。候補キーは、リレーションの中に複数存在することがあります。主キーは候補キーの中からひとつだけ選んだものであり、一つのリレーションの中に一つしかありません。
一意性制約と参照制約以外の整合性制約としてどのようなものが考えられますか? A10 例えば、属性の値に一定の規則を設けて、規則に反する値を許さないという制約があります。これを検査制約といいます。属性の定義域に含まれない属性値を禁止する制約として定義域制約があります。定義域制約は検査制約の一種と考えられます。
■3. リレーショナルデータベースの設計■ Q11 複数の値をもつ属性が2個以上ある場合は、属性の値をタプルにどのように分解するのですか? A11 イラストに示した例を通して考えてみます。上の店舗リレーションの商品種別属性には、店舗番号の店舗で扱う商品種別の集合が、支払種別属性には現金以外の取り扱い可能な支払種別の集合が保持されます。ここでは、支払種別を制限するような特殊な商品は存在しないとします。そうすると、支払種別は店舗によってだけ決まります。これらの集合をタプルに分解する場合、商品種別と支払種別の二つの集合の要素をどのように組み合わせるかが問題になります。商品種別も支払種別も店舗によってだけ決まるので、これらの二つの集合の要素間に関連性はありません。例えば、商品種別食料品の支払いには電子マネーAも電子マネーBも使用でき、特定の一つの支払方法だけが可能なわけではありません。従って、二つの集合の直積を求めてタプルを構成する必要があります。下の店舗リレーションに集合値をタプルに分解した結果を示します。 
複数のタプルを更新することが何故異状なのですか? A12 確かに余分な更新が必要になることは、データ間の関連性の情報が失われたり、主キーとして不当な値が設定されることに比べると、不具合の深刻さが低いとも考えられます。しかし、同じ更新を1回だけではなく複数回行わなくてはならないため、必要な更新がもれる可能性もでてきます。このようなことがあると、本来同じであるデータ間の不一致が起きることになりリレーションが不正な状態になるので、やはり重大な問題と考えられます。
{ 社員番号, プロジェクト番号} → 社員番号 という関数従属性も存在しますか? A13 属性の集合の組合せの値が決まると、その一部の属性の値も決まります。従って、{ 社員番号, プロジェクト番号} → 社員番号という関数従属性は存在します。これは当然の事実なので、自明な関数従属性と言います。
リレーションは何故重複排除されるのですか? A14 集合の要素はその値によってだけ区別されます。従って同じ値の要素は一つの同一の要素とみなされます。リレーションはタプルの集合なので、同じ内容のタプルはリレーションの中にただ一つだけ存在することになります。
リレーションをより高い正規形に分解すると問合せを行うためのリレーショナル演算が複雑になりませんか? A15 複数のリレーションのデータを一つの問い合わせで行うためには、結合のようなリレーショナル演算が必要になり、一般的にひとつのリレーションに必要なデータがすべて含まれる場合に比べて問合せは複雑になります。しかし、データの変更によってデータ間の関連性が失われたり、データが不整合な状態になることは致命的な問題なので、これを避けるためにはリレーションを正規形に分割します。ただし、現実には問合せが複雑になって問合せに時間を要することも重大な問題なので、変更の機会が少なく問合せ中心である等、用途に応じて、低次の正規形に留めるなどのような対処がされることもあります。
■4. データベース言語SQL■ Q16 SQLのスキーマはリレーショナルモデルのリレーションスキーマに相当するものですか? A16 リレーショナルモデルでのリレーションスキーマはリレーションの形式を示すものです。SQLでは表の形式は表の定義内容によって規定されるので、これがリレーションスキーマに相当すると考えられます。SQLのスキーマは、例えば業務ごとに表をまとめるための、表を定義する論理上の場所のことであり、リレーショナルモデルにおいて、これに対応するものはありません。
異なるスキーマに同じ名前の表を定義できますか? A17 同じスキーマに同じ名前の表を定義することはできませんが、異なるスキーマに同じ名前の表を定義することはできます。スキーマにはスキーマ名があり、スキーマ名と表の名前を合わせて一つの名前と考えると、異なるスキーマの同じ名前の表の名前も異なる名前と考えることができます(名の部分は同じでも氏名が異なるのと同じようなことです)。
定義された表を削除したり、定義内容を変更することはできますか? A18 表を削除するためにはDROP TABLE文、表の定義内容を変更するためにはALTER TABLE文を使用します。ALTER TABLE文では例えば列を追加するようなことができます。
主キーでない候補キーを定義することはできますか? A19 PRIMARY KEYという指定の代わりにUNIQUEを指定することによって主キーでない候補キーが定義できます。
条件や選択項目の中に算術演算などの式を指定することはできますか? A20 算術演算をはじめとする各種の演算とそれを組み合わせた式を指定することができます。加減乗除のための算術演算子はイラストの表のとおりです。演算を組み合わせる場合、演算の優先順位を明示する場合には、丸括弧「(」、「)」を使用します(通常の算術的記法と同様です)。例えば、次のような条件を指定することができます。 (基本単価 + 20000) * 1.2 + 100000 >= 200000 
問合せの結果に表の列をすべて指定する場合、明示的に全列を羅列する以外に指定方法はないのですか? A21 FROM句に指定する表のすべての列を問合せ結果項目として羅列するのと等価な指定方法として*指定があります。例えば、次の問合せでは社員表、担当社員表の順で、これらの表のすべての列を表に定義した順番に問合せ結果項目として指定するのと同じになります。 SELECT * FROM 社員, 担当社員 アプリケーションプログラムの中に*を指定する問合せがある場合、表に列を追加すると問合せの結果の列数が変わり、アプリケーションプログラムの修正が必要になることには注意を要します(アプリケーションプログラムの中では、可能な限り問合せ結果項目を明示的に書く方が問題が発生しにくいと考えられます)。
IS NULLは = NULLともかけるのですか? A22 NULLに「=」を適用した結果は不定となります。 「=」という比較述語を使って WHERE句を作った場合、判定結果が真となる行のみが選択されます。 従って、= NULLとは書けません。 (NULLに対する比較、例えばINTEGER型の列CとNULLの等比較を実際に記述する場合、NULLにデータ型を与えるためのCAST指定を使用する必要があります。C = CAST(NULL AS INTEGER)のように指定します。)
一つのSQL文で複数の異なるスキーマの表に問合せを行うことはできますか? A23 通常は、実行するアプリケーションごとにSQLの問合せやデータ操作の対象となる表のスキーマが決められます。これを既定のスキーマと言います。既定のスキーマ以外のスキーマの表をSQL文中に指定する場合は、スキーマ名で修飾する必要があります。例えばFROM句にWORKRECというスキーマの就業履歴表を指定する場合、次のように指定します。 FROM WORKREC.就業履歴 次の問合せは、開発1課の社員の日ごとの出勤時刻と退勤時刻を求めています。ここでの既定のスキーマは社員表を定義しているHRMというスキーマだとします。 SELECT WKR.社員番号, WKR.就業日付, WKR.出勤時刻, WKR.退勤時刻 FROM 社員 EMP, WORKREC.就業履歴 WKR WHERE EMP.社員番号 = WKR.社員番号 AND EMP.所属部署 = '開発1課' この問合せの中のEMPとWKRという名前は、社員とWORKREC.就業履歴の行を参照するための名前で相関名と呼ばれます。
表全体に対する集計を行うためにはどのようにすればよいのですか? A24 表全体に対する集計を行うためには、表全体を一つのグループにする必要があります。GROUP BY句を指定せずに、選択項目に集合関数を指定することにより、表全体(正確に言うとFROM句とWHERE句の結果)を一つのグループにすることができます。例えば、次の問合せによって社員の人数を求めることができます。 SELECT COUNT(*) FROM 社員
集合関数を指定する選択項目の名前はどうなるのですか? A25 選択項目として集合関数や演算式を指定する場合、それらに対応する問合せ結果の項目の名前がどうなるかは、DBMSによって決められます。これでは問合せ結果がどう表示されるのかわからないので、名前を付与するためにAS句という指定があります。例えば、 SELECT COUNT(*) AS 社員数 FROM 社員 というように指定することによってCOUNT(*)の結果に社員数という項目名をつけることができます。キーワードASは省略してもかまいません。AS句は集合関数や演算式だけではなく、問合せ結果の項目の名前を表の列名と異なる名前にする場合にも使用できます。 SELECT EMPNO AS 社員番号 FROM EMP
■5. データベース管理システム■ Q26 表の結合を実際にDBMSが処理するときも、直積をまず求めて選択するという手続きになるのですか? A26 表を結合するときにまず直積を行いその結果から行を選択するというのは、結合の結果を規定するための考え方に過ぎません。規定された結果と同じになればDBMSはどのように処理を行ってもかまいません。もちろん、直積を求めてから行を選択してもよいのですが、結合する表の行数が多いと直積の結果の行数は膨大になります。このため、実際には直積を求めた結果から選択を行うよりも効率的に結合を行う方法が用いられます。
最適化の手法にはどのようなものがありますか? A27 最適化には、ルールベースのものと、コストベースのものの2つの形態があります。 まず、ルールベース最適化は、インデクス部を構成するアクセス法の有無やSQL文で指定される比較演算子によって実行手順の優先度付けを決定しています。そのため、長所としては、予め実行手順の優先度付けが明確かつ規則的なので、ユーザが実行手順をある程度正確に制御ができる点です。しかし、表の全行数、列値の分布など種々の統計量を用いた処理時間の推定を経ずに実行手順を決めてしまうので、非常に処理時間を要する実行手順を選択する確率が高くなってしまいます。 一方で、コストベース最適化は、種々の統計量を用いて処理時間を推定し、最も問合せの処理時間が短くなる実行手順を作成することができます。例えば、統計量として、表の全行数、ページ当りの平均行数、行の平均サイズ、列値の分布、インデクスの深さ、列値の最大値及び最小値、インデクスの葉ページ数など多様な情報を利用しています。長所としては、統計量を取得さえすれば、最適化の実装を理解しなくても、定量的な判断を基にして最小限の性能が保証されることです。反面、ユーザがきめ細かくシステムのチューニングを実施したい場合、実行手順を事前に予測したり、予測した通りに実行手順が作成される保証がないなど、扱い難い状況も発生し得ます。 このコストベース最適化は、実装の詳細をユーザに理解させず済むので、本来DBMSが求める姿であり、多くの製品が採用しています。
他に有用なアクセス法としてどのようなものがありますか? A28 B+木を使うインデクス法、ハッシュ構造を使うハッシュ法以外に、ビットマップインデクス、転置インデクスが知られています。 ビットマップインデクスは出現キー値数が少ない場合に好適なインデクスです。例えば、「男」または「女」の「性別」を表す列であれば、B木インデクスよりも格納効率が良くなります。具体的には、それぞれのキー値毎にビットの配列であるビットマップを作成し、その各ビットでレコードが該当キーを含んでいるかを示します。また、複数のビットマップインデクス同士でビット演算を行うことにより、検索処理の高速化を図ることもできます。 また、転置インデクスは、B木インデクスのように1つの行は1つのキー値のだけを持つことを前提とせずに、1つの行から複数のキーが抽出され得ることを許しています。この転置インデクスは、配列の各要素を検索する場合、及び文書を全文検索する場合に、好適に利用することができます。
B木とB+木の違いはどこですか? A29 B木とB+木の違いは、B木が根ノード及び中間ノードに行の格納位置を保持しますが、一方でB+木が根ノード及び中間ノードには行の格納位置を持たないところです。そのために、B木はB+木と比較して記憶領域が少なくて済む利点がありますが、逆にB木は葉ノード以外でも行の格納位置を持つためにレコードの削除処理が複雑になる扱い難い面もあります。また、B+木は範囲検索やキー値順序のアクセスの場合、葉ノードだけを辿ることで済むので、DBMSのB木インデクスではB+木を実装するものが多くなっています。
ハッシュ関数はどのように決められていますか? A30 キー値にハッシュ関数を適用して行群が格納されるバケットが決められますが、なるべく特定のバケットに集中することなく、すべてのバケットにほぼ同数の行群が格納されることが望まれます。このために、割り算法と呼ばれる変換法がよく利用されています。即ち、キーをコードに分解して、キーを構成するそれらのコードを数値とみなしてすべて掛け合わせた積をバケット数で割り算し、その余りをハッシュ値とするものです。
■6. トランザクション管理■ Q31 ロック方式はどのような仕組みですか? A31 すべてのトランザクションで、読み書きに必要なロックが完了する以前にそれらがアンロックされることはありません。この仕組みを2相ロッキングプロトコル(2PL)と呼びます。2PLでは、データ項目をロックする第1相(成長相)とデータ項目をアンロックする第2相(縮退相)からなり、ロック両立性行列に従い制御します。
デッドロックとはどのような現象を言いますか? A32 並行に処理されているトランザクション同士で、互いにデータ項目をロックし合って、互いに実行できない状態を指します。 また、トランザクション同士で、互いにデータ項目をロックしている関係で有向グラフを作成し、その有向グラフでループを検出すれば、デッドロックが発生していることが検知可能です。デッドロック状態を解消するには、お互いにデータ項目を待ちあっているので、いずれかのトランザクションをROLLBACK処理することにします。これによって、ROLLBACK処理されたトランザクションがロックしていたデータ項目をアンロックするので、待ち状態が解消されてもう一方のトランザクション処理を実行することができます。
ロックはDBMSが自動的にやってくれるのですか? A33 ロック方式の目的は、同じ資源に対する同時要求を直列に処理するように制御し、一つの処理要求が終了するまで他の処理要求を待たせることで、データベースの整合性を保つことです。このロック方式では、ロックの範囲の決め方が重要です。 ロックの範囲を大きくすると、待ちが生じる可能性が高くトランザクション間で競合する確率が高くなり、処理効率に影響が出てきます。そのため、データベースの整合性を保つことのできる程度に範囲を小さくすることが望まれます。例えば、データベースの管理単位として、表、行の順の細かさでロックの取得単位が考えられます。この「細かさ」のことを、ロックの粒度(グラニュラリティ)といいます。 一方で、ロックの範囲を細かくすると、より細かな粒度でロックを取得するので、ロック管理のための負荷が大きくなり、またデータベースの整合性を維持することが難しくなります。 従って、ロックの範囲は、典型的なトレードオフの問題です。このため、ロックの範囲は、DBMSが自動的に決めるだけではなく、アプリケーションで適切なロックの範囲を指定できるようにしており、利便性を図っています。
チェックポイントの間隔はどのように決めればよいのですか? A34 チェックポイントの間隔決定方法にはいくつかの考え方があります。例えば、一定時間間隔毎に行うことや、一定数のトランザクションを実行する毎に行うなどが考えられます。もし、チェックポイント法を採用しなければ、チェックポイント処理の実行のための時間が掛からないので、システム障害が発生しなければ、それだけトランザクション処理が多く実行できスループットが向上します。 一方で、もしシステム障害が発生すれば、システム障害時点以前までに実行したすべてのトランザクションをUNDOしてからREDOしなければならず、障害回復に膨大な時間を要します。 従って、チェクポイントの間隔を決定する方法は、典型的なトレードオフの問題です。
UNDO、REDO、COMMIT処理、及びROLLBACK処理はDBMSが自動的にやるのですか? A35 トランザクションは、データベースに対するアプリケーションレベルでの一つの原子的な処理として扱う単位です。この処理単位の中には、SQLのSELECT文やINSERT文、UPDATE文、DELETE文のようなデータベースの更新がいくつか組み合わされて含まれ、その結果アプリケーションとして意味のある処理が形作られます。そのため、このトランザクションで実行された結果をデータベースに反映するのか、あるいは全く結果が反映されないようにするのかは、アプリケーションに任されています。即ち、アプリケーションにとって中途半端な処理状態を残さないために、COMMIT処理及びROLLBACK処理は、DBMSが自動的に実行する訳ではなく、陽にアプリケーションが指示する必要があります。 一方、データベースシステムに障害が発生した場合、DBMSはトランザクションを単位として障害回復を行います。その際には、DBMSは障害発生以前に実行されていた各トランザクションをREDOすべきかUNDOすべきかを判断します。即ち、DBMSはREDO及びUNDOを自動的に実行します。
■7. データベースシステムの応用■ Q36 TPモニタとはどのようなソフトウェアですか? A36 トランザクション処理の監視及び制御を行うソフトウェアです。略して、トランザクション処理モニタ(TP Monitor:Transaction Processing monitor)とも呼ばれ、グローバルトランザクション管理及びアプリケーション管理からなります。 データの整合性を保証するグローバルトランザクション管理機能は、トランザクションのログ管理機能、トランザクションの障害回復機能、及び複数のデータベースにまたがるグローバルトランザクションの整合性を保証する2相コミットプロトコルを実現する機能からなります。 また、大量ユーザを支援するアプリケーション管理機能は、トランザクション処理の受付メッセージ管理機能、優先順位付けによるスケジューリング機能、及び負荷均衡化機能からなります。
グローバルトランザクションとはどのようなものですか? A37 異種のサービスが分散してデータベースを提供するシステムで、データの整合性を保証するために、各サービスに対応するローカルトランザクションを一つのグローバルトランザクションとして取り扱い、このグローバルトランザクションを整合性の単位としてACID特性を実現します。そのために、2相コミットプロトコルと呼ぶ分散したデータベースを矛盾なく同時に更新する方式を採用しています。2相からなり、第1相(投票相)でグローバルトランザクションを構成する各ローカルトランザクションがコミット処理が可能か問い合わせ、すべてのローカルトランザクションがコミット処理可能であることを確認します。次の第2相(決定相)で各ローカルトランザクションの更新処理を依頼し、すべてのローカルトランザクションの更新が完了したことを確認した時点でグローバルトランザクションの更新処理が完了したことにします。
並列データベースと分散データベースの違いは何ですか? A38 並列データベースは、データベース処理を高速化する手法であり、データベースを分割して、それらのデータベースに対して各々SQLが並列に実行することで、大規模なデータベースへの高速検索を可能とします。一方、分散データベースは、複数のデータベースがネットワークを介して接続され、あたかも一つのデータベースであるかのように見せることです。
XMLへの問合せ言語とはどのようなものですか? A39 ISO/IEC 9075-14, Information Technology - Database Languages - SQL - Part 14: XML-Ralated Specifications(SQL/XML)で、XMLへの問合せ言語が規定されています。 SQL/XMLは、XMLの階層構造をそのままXML型のデータ構造として利用して、XQuery式によりXMLデータの部分構造を指定してXMLEXISTS述語で条件式を評価したり、またXMLQUERY関数で部分構造を取り出すことができます。
多次元インデクスとはどのようなものですか? A40 マルチメディアに特有な特徴量に着目して検索を高速化する手段として利用されています。例えば、静止画であれば色、模様、形、位置などの特徴量が、また動画であれば静止画と同様な特徴量に加えて、動く方向に関する特徴量が、それぞれ利用されています。 検索の対象となるマルチメディアのデータの集合から、これらの特徴量に基づいて多次元の特徴量ベクトルを算出し、その特徴量ベクトルから1次元の順序性を持つキー値を近似して計算します。このキー値を使って、B木インデクスを構成することで検索の高速化を図ることができます。
|