|
■1. 既存のデータ分析■
Q1.データウェアハウスはどのようなものですか? ■2. 知識発見のプロセス■ Q2.知識発見プロセスにデータマイニングは必要ですか? Q3.データマイニングという言葉の定義はなんですか? Q4.データウェアハウスはどのような意図で作成されていますか? Q5.データベースとデータウェアハウスの使い方にどのような違いがありますか? Q6.トランザクションとは商品アイテムを集めたデータだけですか? Q7.どんなことでも予測できますか? Q8.データ間の距離計算で偏りが出ませんか? ■3. 頻出パターンと相関ルール抽出■ Q9.最小支持度、最小確信度はどの程度の値が適切ですか? Q10.確信度が高いルールほど重要なのですか? Q11.同時に購入する商品アイテムは人それぞれ違うのではないですか? Q12.取引を行った日時などの時間情報は相関ルール抽出に利用しないのですか? Q13.頻出パターンと相関ルールはどう使い分ければよいのですか? ■4. データ分類と予測■ Q14.数字以外の変数はカテゴリ値ですか? Q15.物理学にもエントロピーがありますが何か関係ありますか? Q16.決定木・回帰木は二分木にしなくてはならないのですか? Q17.データに欠損値がある場合、どのように対処しますか? Q18.学習データが更新あるいは追加された場合、どのように対処しますか? ■5. クラスタリング■ Q19.クラスタ数はいくつくらいが適切ですか? Q20.あるデータが複数のクラスタに属する場合はないのですか? Q21.値域の異なるすべての変数を同じように扱ってもよいのですか? Q22.円形ではなく複雑な形をもつクラスタは作れないのですか? Q23.変数が多数あるデータベース、つまり高次元のデータベースに対処する方法はありますか? ■6. データマイニングの応用事例と展望■ Q24.顧客の声はどのようにして記録されるのですか? Q25.評判分析に使う他の技術は何ですか? Q26.属性数の多いデータベースに対処する方法はありますか? Q27.大規模なデータベースを効果的に処理するテクニックはありますか? ■1. 既存のデータ分析■ Q1 データウェアハウスはどのようなものですか? A1 データウェアハウスは、狭義ではデータを活用するための倉庫を指します。また、広義では企業におけるデータ、情報、知識の活用におけるプロセス、経営手法を指すことがあります。このレッスンでは、データウェアハウスを企業が戦略的にデータを活用するための倉庫と考えます。
Q2 知識発見プロセスにデータマイニングは必要ですか? A2 実世界で発生する大量のデータを扱う現代において、人が調査できるデータ量には限界があります。大量のデータから未知のルール、モデルを発見するデータマイニングは、知識発見プロセスにおいて重要な技術といえます。
データマイニングという言葉の定義はなんですか? A3 データマイニングは、文字通り「データという鉱山から鉱脈を発掘する」を意味しますが、大量のデータから有用な知識を発見するという期待が込められています。1995年に開催されたKDD(Knowledge Discovery in Database)の国際会議で、「KDDはデータベースから知識を抽出するプロセス全体を記述するために使い、データマイニングはKDDプロセスの知識発見段階に使用する」と定義されています。このレッスンでは、データマイニングはKDDプロセスの知識発見段階としています。
データウェアハウスはどのような意図で作成されていますか? A4 データウェアハウスは、活用の目的別に整理される「サブジェクト指向」、データを統一・一元化する「統合」、時間との繋がりをもつ「時系列性」、データを更新しない「恒常性」の特徴を有し、企業が戦略的にデータを活用する意図で作成されています。
データベースとデータウェアハウスの使い方にどのような違いがありますか? A5 データベースは、受発注処理、在庫処理、発送処理という日々の企業活動で起こったことを記録するため使われます。一方で、データウェアハウスは、マーケティングや生産管理など企業レベルの意思決定を支援するために使われます。
トランザクションとは商品アイテムを集めたデータだけですか? A6 企業情報システムでは、誰がいつどこで何をどうしたか、という日々の企業活動で起こったことの一つひとつを記録する処理単位をトランザクションと呼ぶことがあります。OLTP(On-Line Transaction Processing)では、仕入伝票や納品票に記載されている1行分のデータを処理単位にしてデータベースに記録します。
どんなことでも予測できますか? A7 分類と予測によって作成される決定木を使う予測は、過去の履歴データを使って学習した結果を基にして行われます。予測は学習で使った履歴データから将来に起き得る行動の予測を行うので、まったく新たな商品の購入予測などには使えません。
データ間の距離計算で偏りが出ませんか? A8 数値データの比較は2つのデータ間の距離計算によって行われるために、値の振れ幅が異なる属性が存在すると距離計算に偏りが生じることがあります。例えば、0から100までの値を取る属性は、0から1までの値を取る属性と比較して、2点間の距離が長くなります。この偏りを防ぐために、各属性値を[0,1]のスケールで整形します。
Q9 最小支持度、最小確信度はどの程度の値が適切ですか? A9 アプリケーションや総アイテム数、1取引の平均アイテム数などに応じて適切な数値が異なるので、様々な最小支持度、最小確信度値で実行してみて最適な値を探していくのが一般的です。ただし、最小支持度が極端に小さい場合、計算時間が増大するので、初めは、ある程度大きな最小支持度で実行し、出力されるルール数を確認するのがよいでしょう。
確信度が高いルールほど重要なのですか? A10 そうとは限りません。支持度の高いアイテム集合が右辺にあるルールは高い確信度となる傾向があります。一般的には、右辺のアイテム集合の支持度と確信度との差が小さいルールは「あたりまえ」のルールで、確信度と、右辺のアイテム集合の支持度との差が大きいルールほど重要と言ってよいでしょう。
同時に購入する商品アイテムは人それぞれ違うのではないですか? A11 もちろん人それぞれ違います。データベースにはいろいろな人の取引記録が大量に記録されており、そこから抽出されるルールは、その支持度が高い場合、ある程度、多くの人が同時に購入したと類推できます。
取引を行った日時などの時間情報は相関ルール抽出に利用しないのですか? A12 時間情報、とくに発生順序を考慮した相関ルール抽出問題もあります。例えば、『「ビール」を買った顧客は、その後、近いうちに「ブランデー」を購入する確率が高い』といった相関ルールも抽出することができます。このような相関ルールを「シーケンシャルパターン」と呼びます。ただし、「シーケンシャルパターン」を抽出するためには、各取引番号がどのユーザIDのものかわかる状態のデータベースが必要です。近年は、ポイントカードなどが広く普及していますが、ポイントカードを利用した取引には、「シーケンシャルパターン」抽出のために必要なID情報が含まれています。
頻出パターンと相関ルールはどう使い分ければよいのですか? A13 頻出パターンを見れば、その集合内のアイテムが同時に起こりやすいことがわかります。このような知見は多くのアプリケーションで有用です。しかし、あるアイテムに注目した分析を行う場合、そのアイテムを右辺に持つ相関ルールの確信度が、重要な知見となる場合があります。例えば、右辺にアイテムAを持つ相関ルールの確信度がとても高い場合、その相関ルールの左辺のアイテム集合がアイテムAに関して重要と考えられます。そのような場合、相関ルールの分析が役に立ちます。
Q14 数字以外の変数はカテゴリ値ですか? A14 数字以外のデータでも数値と扱うべきものがあります。例えば、成績がA、B、C、Dで記録されている場合、この成績データはカテゴリ値として扱うこともできますが、数値として扱うこともできます。この成績変数を数値として扱う場合、「成績≧C(成績値がC以上かどうか)」のような分類規則を定義できます。数値として扱うことができる変数は、この成績のように順序のある値をもつ変数です。
物理学にもエントロピーがありますが何か関係ありますか? A15 物理学でエントロピーは「乱雑さ」を表す量で、その考え方は似ています。
決定木・回帰木は二分木にしなくてはならないのですか? A16 N個の値をもつカテゴリ値の変数で分類する際に、N個の子ノードを持つ頂点が作られることもあります。例えば、「血液型」という変数が「A」、「B」、「O」、「AB」の4値を持つ場合、下図のように4つの子ノードをもつ頂点を作ることもあります。 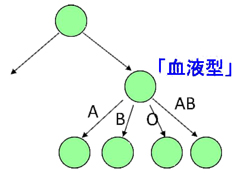
データに欠損値がある場合、どのように対処しますか? A17 実際のデータベースには、一部のデータ内に欠損値が含まれることも多く、それに対処する手法もいろいろ考案されています。代表的な対処法として、欠損値の部分に、その変数の平均値あるいは最頻値を代入する方法があります。
学習データが更新あるいは追加された場合、どのように対処しますか? A18 学習データに対する更新や追加が微細なものなら無視してもよい場合もありますが、更新や追加が多い場合は決定木、回帰木を最初から再作成します。
Q19 クラスタ数はいくつくらいが適切ですか? A19 アプリケーションやデータ内容次第です。あらかじめ必要なクラスタ数があれば、その数になるようにクラスタリングすべきですがない場合は、クラスタ内距離をできるだけ小さくし、かつ、クラスタ間距離をできるだけ大きくするという基準に従って適切なクラスタ数を決めます。
あるデータが複数のクラスタに属する場合はないのですか? A20 本レッスンでは、あるデータが必ずいずれか一つのクラスタに属するクラスタリングを扱っています。これをハードクラスタリングと呼びます。データが複数のクラスタに属することを許すクラスタリング、つまり、オーバーラップするクラスタが存在するクラスタリングもあります。これをソフトクラスタリングと呼びます。
値域の異なるすべての変数を同じように扱ってもよいのですか? A21 クラスタリングを行う前に可能なかぎり、変数間の値域を平滑化します。例えば、すべての変数値が0から1の値をとるように変換します。
円形ではなく複雑な形をもつクラスタは作れないのですか? A22 カーネル関数などで非線形変換を行った後でクラスタリングすると複雑な形のクラスタを作成することができます。複雑な形のクラスタを作成するクラスタリングのことを非線形クラスタリングと呼びます。
変数が多数あるデータベース、つまり高次元のデータベースに対処する方法はありますか? A23 高次元のデータベースに対しては、特異値分解などの次元削減を適用することもあります。
Q24 顧客の声はどのようにして記録されるのですか? A24 コールセンタの担当者が顧客との応答の概要をキーボードで入力するのが一般的です。近年では、入力の手間を省くと共に、全ての会話内容をテキスト化して分析しようと、自動音声認識を活用する試みも始まっています。
評判分析に使う他の技術は何ですか? A25 ウェブ上の情報を分析するにはテキストマイニングの技術が必要です。テキストマイニングとは日本語や英語などの自然言語を使って作成されたテキスト文書を分析し、評判などの情報を抽出する技術で、自然言語処理技術とも呼ばれます。
属性数の多いデータベースに対処する方法はありますか? A26 属性数の多いデータベースは多次元データとも呼ばれます。あまりに属性数が多い場合、計算時間や使用メモリ容量の面で問題となることがあります。そのような場合には次元削減を行います。次元削減の代表的な手法の一つに「特異値分解」があります。
大規模なデータベースを効果的に処理するテクニックはありますか? A27 多くのデータマイニング技術は大規模なデータにも対応できますが、それでも大量のデータを処理するには計算時間や使用メモリ容量の面で問題となることがあります。その場合、データ集約を行うことが有効です。例えば、「商品ID、日時、店舗ID」が記録された個々商品の売上を、「日毎、商品ID毎」の売上数に集約したり、「店舗毎、商品ID毎」の売上数に集約するとデータ数を削減することができます。
|